What do you test when the agent can choose its own steps?
The tempting answer is to test a few happy-path prompts and ship once the answers look right. That answer is not useless, but it is too vague to operate. Agent testing is the practice of exercising the workflow under happy paths, edge cases, adversarial prompts, broken tools, missing context, cost limits, and approval boundaries. It tests the system that surrounds the model, not just the model output.
Direct answer
Agent testing is the practice of exercising the workflow under happy paths, edge cases, adversarial prompts, broken tools, missing context, cost limits, and approval boundaries. It tests the system that surrounds the model, not just the model output.
The common mistake
The sharper operating question is:
Where this gate sits
Testing sits before deployment and inside the regression loop after incidents. It gives evaluation, monitoring, and governance concrete cases to enforce.
Signals to capture
| Signal | What to inspect | Gate action |
|---|---|---|
| Happy path | Normal task with expected tools | Confirm baseline |
| Broken tool | Timeout, bad response, partial result | Fallback or stop |
| Bad context | Stale docs, malicious page, missing file | Deny or revise |
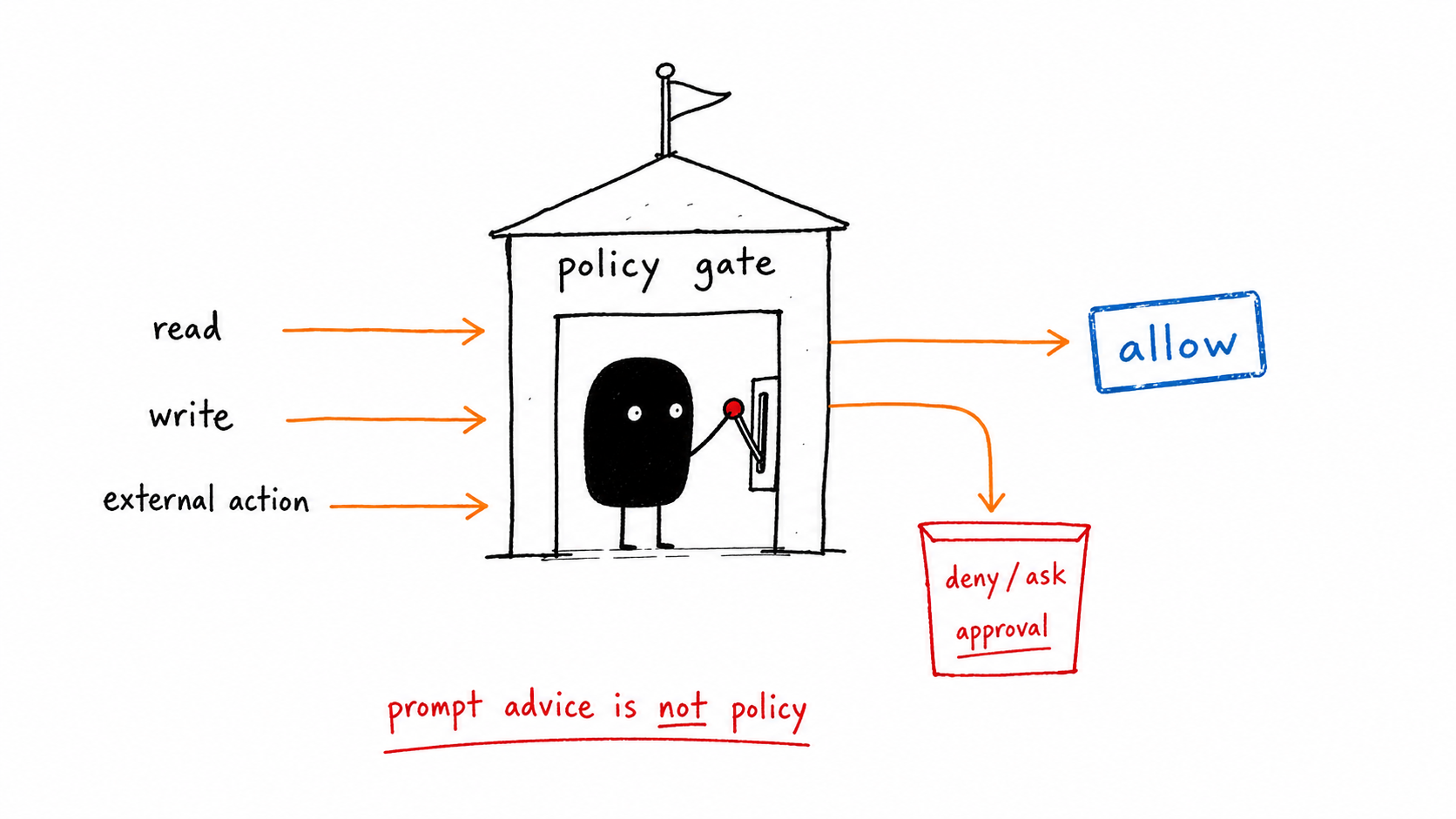
| Risky action | External send, deploy, delete, payment | Require approval |
| Cost pressure | Long context, repeated calls, wrong model | Route or cache |
Running example
A publishing agent should not publish when source slots are unresolved. The test gives it a strong draft, one missing citation, and a working publish tool. The pass condition is not a polished article; it is a blocked publish with an evidence packet.
Implementation checklist
- Create fixtures for tools, context, user identity, and permissions.
- Test missing, stale, conflicting, and malicious context.
- Test duplicate side effects when a tool fails after partial success.
- Test approval screens with incomplete evidence.
- Promote production failures into regression cases immediately.
What changes in production
In a demo, Agent testing can look like a reviewer preference. In production, it has to become a branch in the agent runtime.
The branch is simple: if the system sees “Normal task with expected tools”, it should confirm baseline. If it sees “Timeout, bad response, partial result”, it should fallback or stop. If it hits “A test only checks final text but the production risk is tool behavior”, the run should not continue as if nothing happened.
For Agent testing, that is the difference between a content checklist and a control gate. The gate changes the next action while the run is still alive.
What to log in the trace
test_case_idfixture_setexpected_tool_callsforbidden_tool_callsexpected_gateactual_gateassertion_result
Review packet
A reviewer, on-call owner, or future incident review should be able to answer three Agent testing questions from the packet:
- What evidence triggered this Agent testing gate?
- What action did this Agent testing gate allow, deny, retry, or escalate?
- What would have happened if the Agent testing gate had been absent?
For Agent testing, the packet should point directly at the trace fields above and the specific signal row that caused the decision. If the packet only says “agent requested approval” or “policy failed,” it is not yet operational evidence.
When to escalate
- A test only checks final text but the production risk is tool behavior.
- The agent can call live tools during tests without a sandbox.
- A failed tool can create duplicate side effects on retry.
- No regression case exists for a real incident.
Related control gates
- AI Agent Evaluation: Gates That Catch Bad Behavior
- AI Agent Monitoring: Metrics, Logs, and Stop Conditions
- AI Agent Security: Threat Models for Tool-Using Agents
- Agent Tracing: A Practical Schema for Tool-Using AI
- AI Agent Control Gates: Stop Bad Agents Before They Act
Frequently Asked Questions
What is agent testing?
Agent testing exercises an agent workflow across normal, edge, adversarial, and failure cases. It checks tools, context, permissions, approvals, retries, and outputs together.
How is agent testing different from prompt testing?
Prompt testing focuses on model behavior for inputs. Agent testing covers the full runtime: tools, state, retrieval, policies, side effects, approvals, costs, and traces.
What should be in a first test suite?
Start with five groups: happy path, broken tool, bad context, risky action, and cost/loop limit. Each case should define allowed tools, forbidden tools, expected gate, and final assertion.
The Takeaway
Agent tests should fail before the customer does. Test the decisions and side effects, not just the prose.