AI Agent Evaluation: Gates That Catch Bad Behavior
Did the agent succeed, or did it just finish?
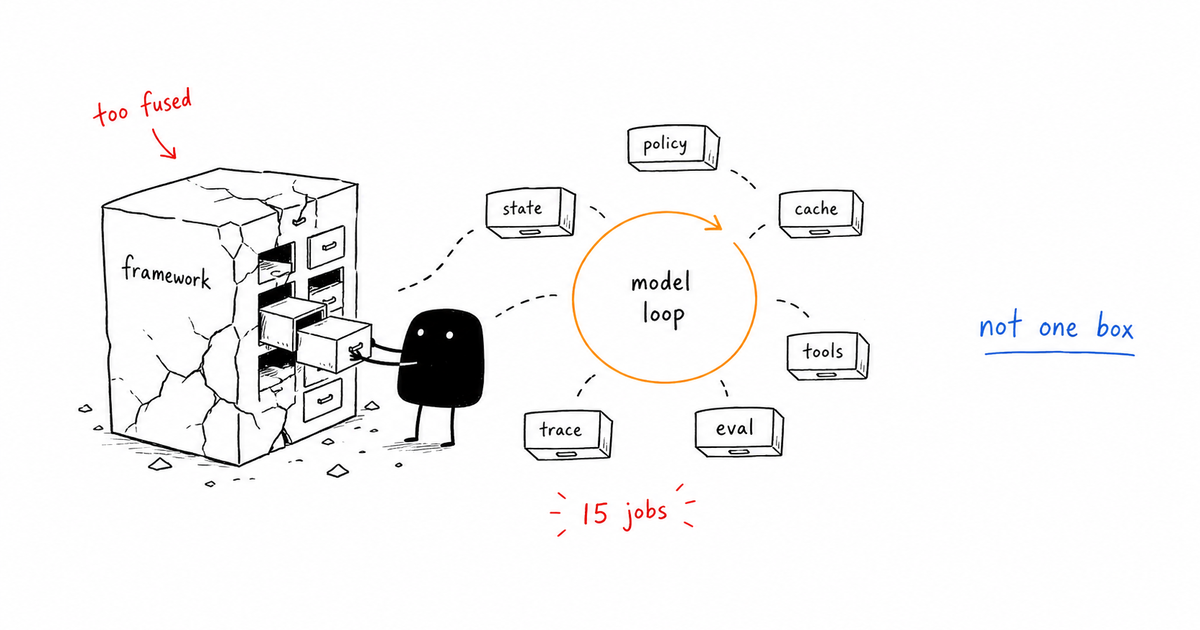
The tempting answer is to score the final answer after the run and ignore the path that produced it. That answer is not useless, but it is too vague to operate. AI agent evaluation tests whether an agent completed the right task with the right evidence, tools, policy decisions, and final action. For production agents, evals should become gates: they decide whether the run can continue, retry, pause, or fail.
Direct answer
AI agent evaluation tests whether an agent completed the right task with the right evidence, tools, policy decisions, and final action. For production agents, evals should become gates: they decide whether the run can continue, retry, pause, or fail.
Data note
When this matters
- The agent produces multi-step work that cannot be judged from final text alone.
- Tool choice, evidence use, or policy compliance matters as much as the answer.
- You need regression checks before changing prompts, models, tools, or context layout.
Failure modes this page should catch
- The final answer sounds good but uses the wrong source.
- The agent calls a tool correctly but for the wrong reason.
- A prompt update improves one task and breaks approval behavior.
- The eval checks final text but ignores trace evidence.
Agent eval gate template
| Gate | Signal | Action |
|---|---|---|
| Task success | did the output solve the request | Pass or revise |
| Evidence | source ids, quotes, retrieved context | Fail if missing |
| Tool correctness | right tool, right input, right scope | Retry or route |
| Policy | permission result and approval path | Block on violation |
| Regression | baseline task suite | Do not deploy on drop |
Running example
A research agent writes a source-backed answer. The eval passes style but fails evidence grounding because two claims have no source ids. The publish gate blocks the final action and returns a concrete fix list.
Copy the working template
Use the agent eval gate template above as the v1 artifact for this page. Replace the placeholders with your own agent names, tools, risk classes, and thresholds, then link the result back into your monitoring, tracing, security, and evaluation gates.
How this connects to the control-gates library
- AI Agent Control Gates: Stop Bad Agents Before They Act
- Agent Testing: Test Plans for Tool-Using AI Systems
- Agent Observability: Trace What Agents Decide and Do
- AI Agent Monitoring: Metrics, Logs, and Stop Conditions
- AI Agent Governance: Approval, Audit, and Eval Gates
Frequently Asked Questions
What is AI agent evaluation?
AI agent evaluation tests the quality, safety, tool use, evidence, and policy compliance of an agent run. In production, those tests should act as gates before risky work continues.
How is agent evaluation different from LLM evaluation?
LLM evaluation often scores model output. Agent evaluation also scores tool choice, retrieved context, policy decisions, approval paths, workflow state, and final side effects.
What should the first eval gate test?
Start with task success, source grounding, tool correctness, and policy compliance. Those checks catch failures that a generic helpfulness score will miss.
The Takeaway
Agent evaluation is only useful when the score can change the workflow: continue, retry, pause, or stop.