LLM Observability: When Basic Telemetry Stops Working
Why did the LLM look healthy while the agent did the wrong work?
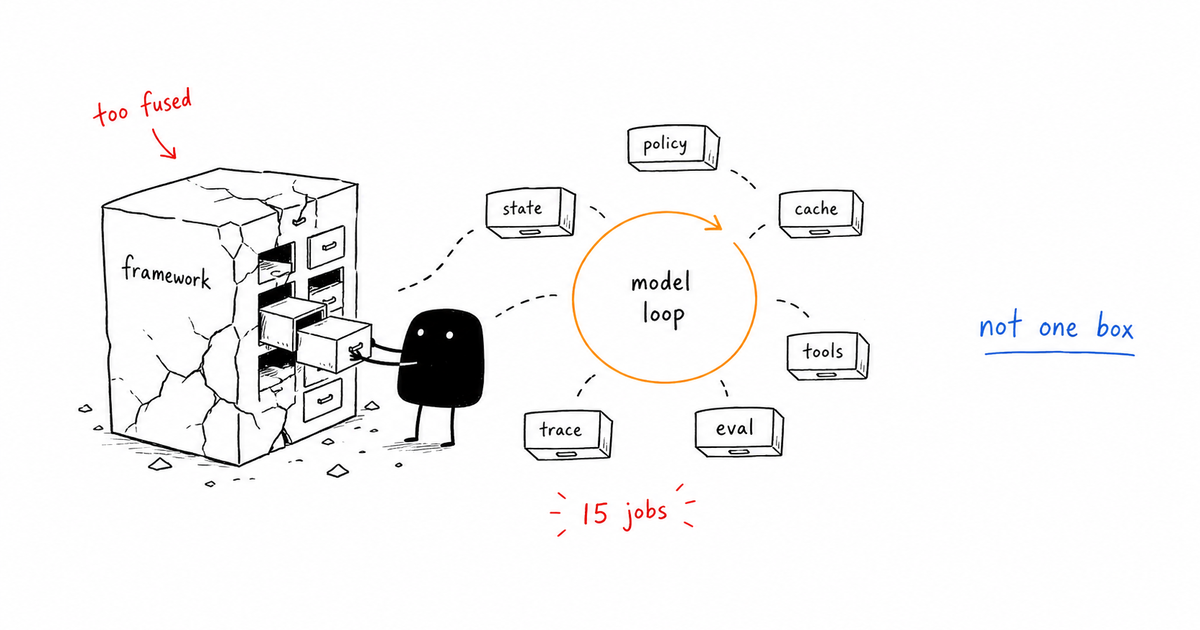
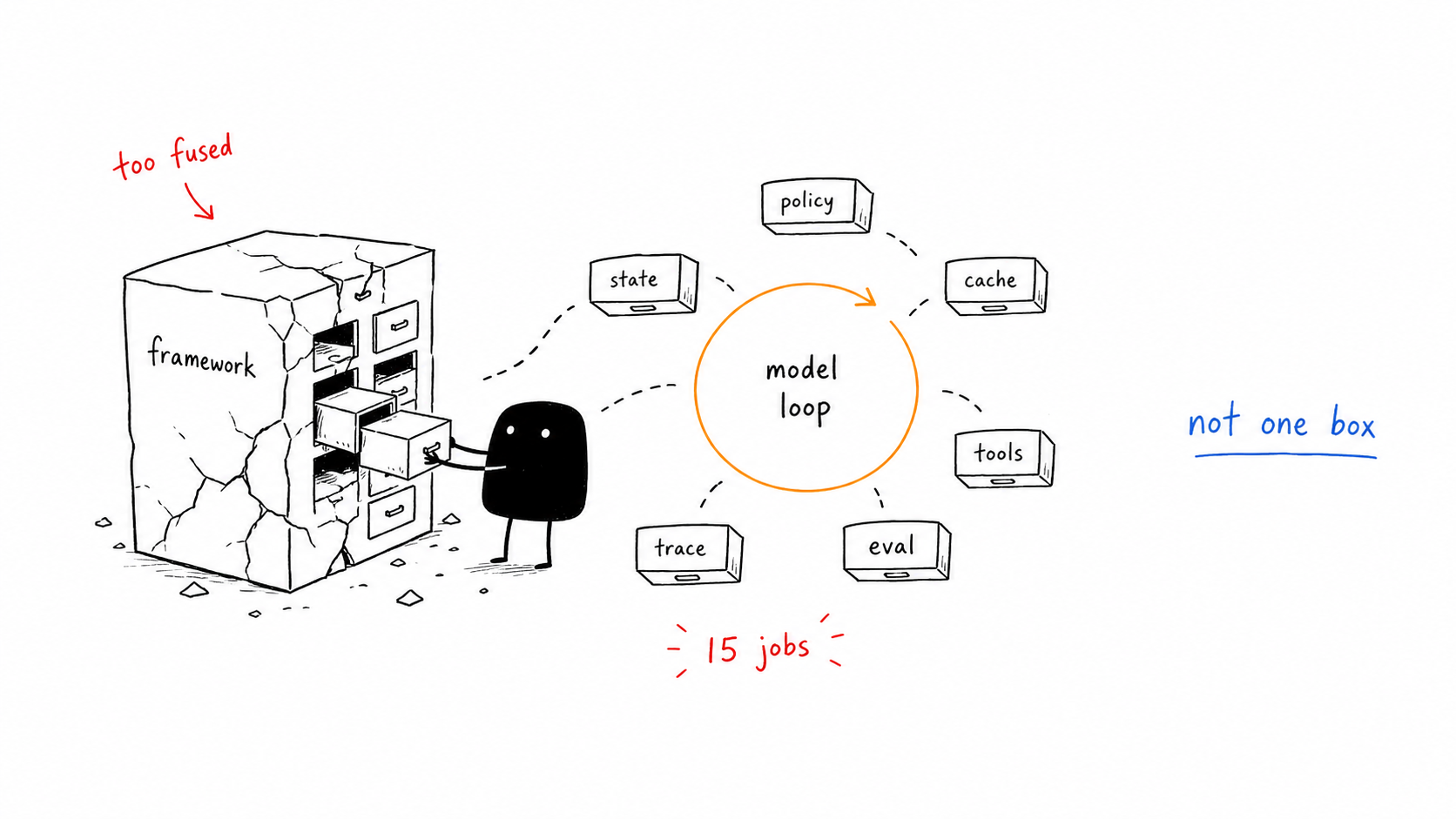
The tempting answer is to treat every model call as the whole system boundary. That answer is not useless, but it is too vague to operate. LLM observability tracks model behavior such as prompts, completions, latency, token usage, errors, and quality checks. It becomes incomplete for agents when the important failure is not the model call itself, but the tool, permission, retrieval, or approval decision around it.
Direct answer
LLM observability tracks model behavior such as prompts, completions, latency, token usage, errors, and quality checks. It becomes incomplete for agents when the important failure is not the model call itself, but the tool, permission, retrieval, or approval decision around it.
Data note
When this matters
- You already log prompts and completions but still cannot explain failed workflows.
- The application has multi-step tool use, not just one model response.
- You need a migration path from model telemetry to agent-level traces.
Failure modes this page should catch
- Model call passed, tool selection failed.
- Token cost is visible, but cache misses are not tied to context layout.
- Prompt and output are logged, but retrieved evidence and policy decisions are missing.
- Quality checks run after the final answer, not before the risky action.
LLM vs agent observability matrix
| Gate | Signal | Action |
|---|---|---|
| LLM span | prompt, model, latency, tokens | Keep as base telemetry |
| Retrieval span | documents, scores, filters | Attach to the model call |
| Tool span | tool, input, output, permission | Trace every external action |
| Eval span | criteria, result, failure reason | Gate publish or retry |
| Approval span | human, decision, rationale | Preserve audit trail |
Running example
A support agent uses the right model and returns a fluent answer, but it called the refund tool before checking customer eligibility. LLM observability says the generation was normal. Agent observability shows the missing policy gate.
Copy the working template
Use the llm vs agent observability matrix above as the v1 artifact for this page. Replace the placeholders with your own agent names, tools, risk classes, and thresholds, then link the result back into your monitoring, tracing, security, and evaluation gates.
How this connects to the control-gates library
- AI Agent Control Gates: Stop Bad Agents Before They Act
- Agent Observability: Trace What Agents Decide and Do
- Agent Tracing: A Practical Schema for Tool-Using AI
- AI Agent Monitoring: Metrics, Logs, and Stop Conditions
- Prompt Caching: Cut Agent Cost Without Breaking Quality
Frequently Asked Questions
What is LLM observability?
LLM observability is visibility into prompts, outputs, token usage, latency, errors, and quality signals for model calls.
Why is agent observability different?
Agents introduce decisions outside the model call: tool selection, retrieval, permissions, approvals, retries, and workflow state. Those need their own trace fields.
Should teams build both?
Yes. Treat LLM observability as the base layer and add agent spans for tools, policy, evals, and approvals when the application becomes agentic.
The Takeaway
LLM observability tells you how the model behaved. Agent observability tells you how the system acted.