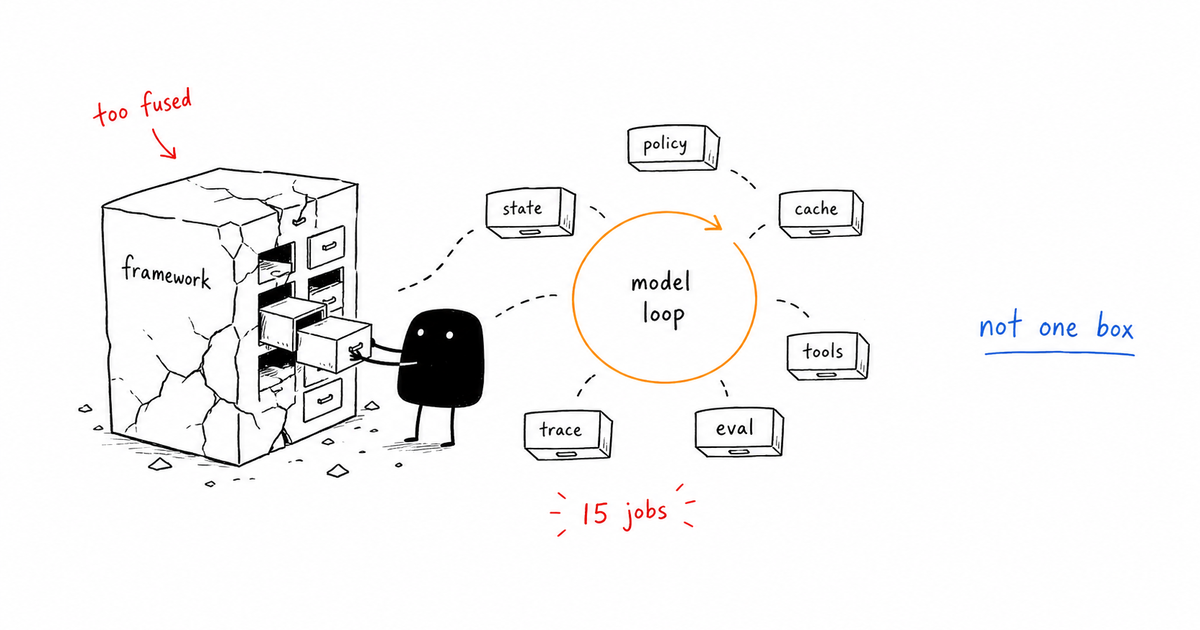
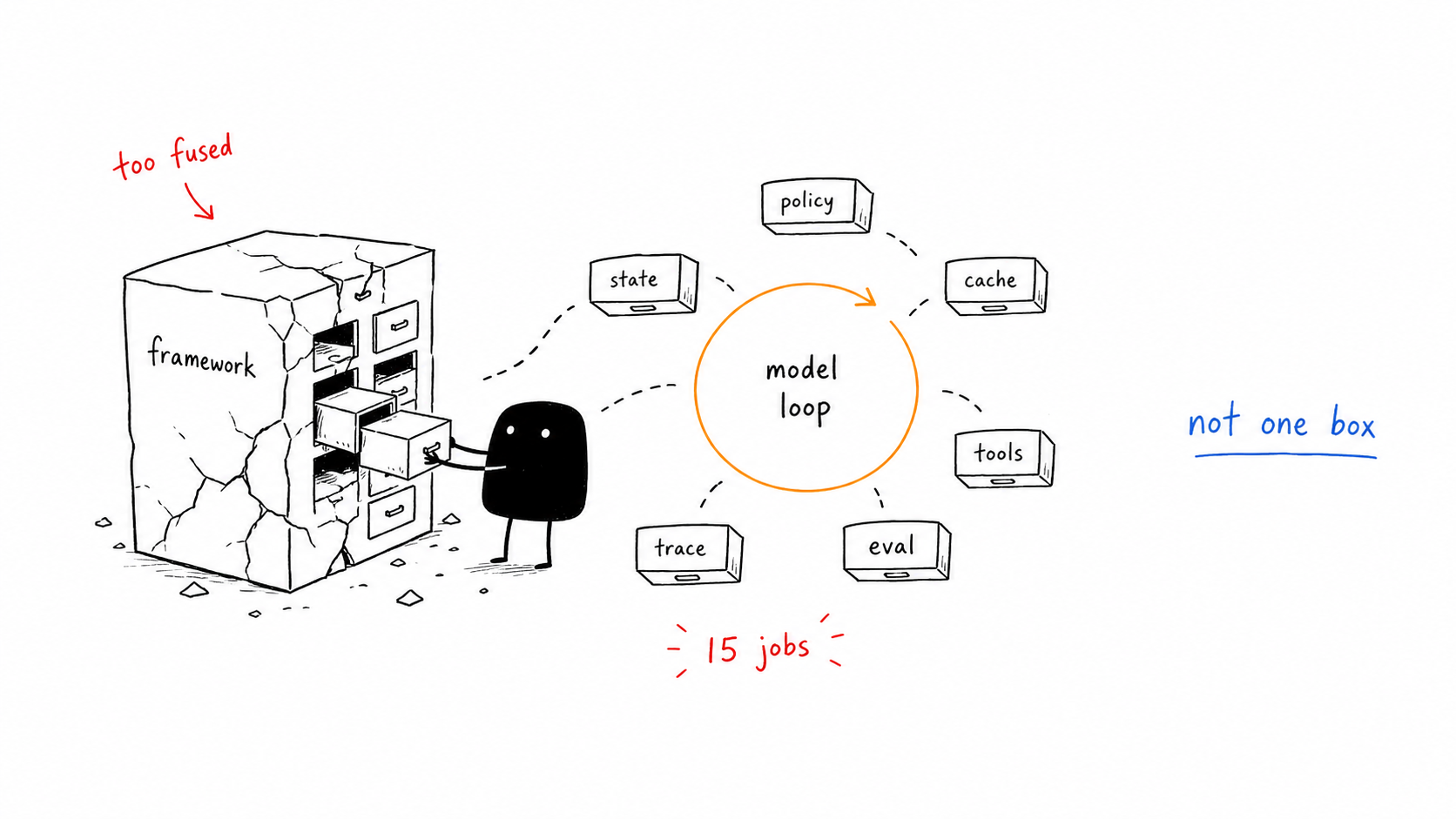
Agent Observability: Trace What Agents Decide and Do
What did the agent know when it chose the wrong tool?
The tempting answer is to save the transcript and read it later when something looks wrong. That answer is not useless, but it is too vague to operate. Agent observability is the ability to reconstruct an agent’s inputs, tool choices, intermediate state, policy decisions, costs, evaluations, and final actions. It is deeper than request logging because the important failure may be the decision path, not the HTTP result.
Direct answer
Agent observability is the ability to reconstruct an agent’s inputs, tool choices, intermediate state, policy decisions, costs, evaluations, and final actions. It is deeper than request logging because the important failure may be the decision path, not the HTTP result.
Data note
When this matters
- The agent can take multiple steps before the user sees an answer.
- A failure requires comparing prompt, retrieved context, tool output, and policy state.
- You need audit trails for customer-visible or security-sensitive actions.
Failure modes this page should catch
- Transcript archaeology: engineers read raw chat logs because no structured trace exists.
- Missing context: the trace records the final answer but not the retrieval that shaped it.
- Tool blindness: tool calls are logged without the reason, scope, or permission result.
- Quality blind spot: no eval result is tied to the final action.
Minimum viable agent trace
| Gate | Signal | Action |
|---|---|---|
| Input | user request, system rules, selected context | Persist immutable turn packet |
| Decision | planned step and selected tool | Record reason and alternatives |
| Permission | scope, policy rule, approval state | Attach policy result to trace |
| Output | tool result, model output, artifacts | Preserve evidence and hashes |
| Quality | eval, verification, user acceptance | Tie outcome to the turn |
{
"turn_id": "turn_123",
"agent_id": "publishing_agent",
"input": {"request": "draft the MCP auth section"},
"context": {"sources": 4, "memory_keys": ["agent_policy"]},
"step": {"name": "fetch_mcp_spec", "tool": "web_fetch"},
"policy": {"result": "allow", "rule": "read_only_source"},
"cost": {"input_tokens": 18420, "output_tokens": 930},
"eval": {"result": "pass", "checks": ["source_present", "no_placeholder"]},
"state": "done"
}Running example
A source summary is wrong. With observability, you can see the retrieved page, the exact tool output, the model step that compressed it, and the eval that missed it. Without observability, you only know the final paragraph was bad.
Copy the working template
Use the minimum viable agent trace above as the v1 artifact for this page. Replace the placeholders with your own agent names, tools, risk classes, and thresholds, then link the result back into your monitoring, tracing, security, and evaluation gates.
How this connects to the control-gates library
- AI Agent Control Gates: Stop Bad Agents Before They Act
- AI Agent Monitoring: Metrics, Logs, and Stop Conditions
- LLM Observability: When Basic Telemetry Stops Working
- Agent Tracing: A Practical Schema for Tool-Using AI
- AI Agent Evaluation: Gates That Catch Bad Behavior
Frequently Asked Questions
What is agent observability?
Agent observability is structured visibility into an agent’s inputs, decisions, tool calls, context, cost, policy decisions, evaluations, and outcomes across a complete turn or workflow.
Is AI agent observability a separate page?
For this cluster, no. The canonical page targets both agent observability and AI agent observability because the search intent overlaps and splitting them would create near-duplicate pages.
What should a trace capture first?
Capture the turn id, selected context, tool call, policy result, cost, model output, eval result, and final state. That is enough to debug most early failures.
The Takeaway
Observability is the record that makes autonomy inspectable. If you cannot reconstruct the decision, you cannot safely improve the agent.