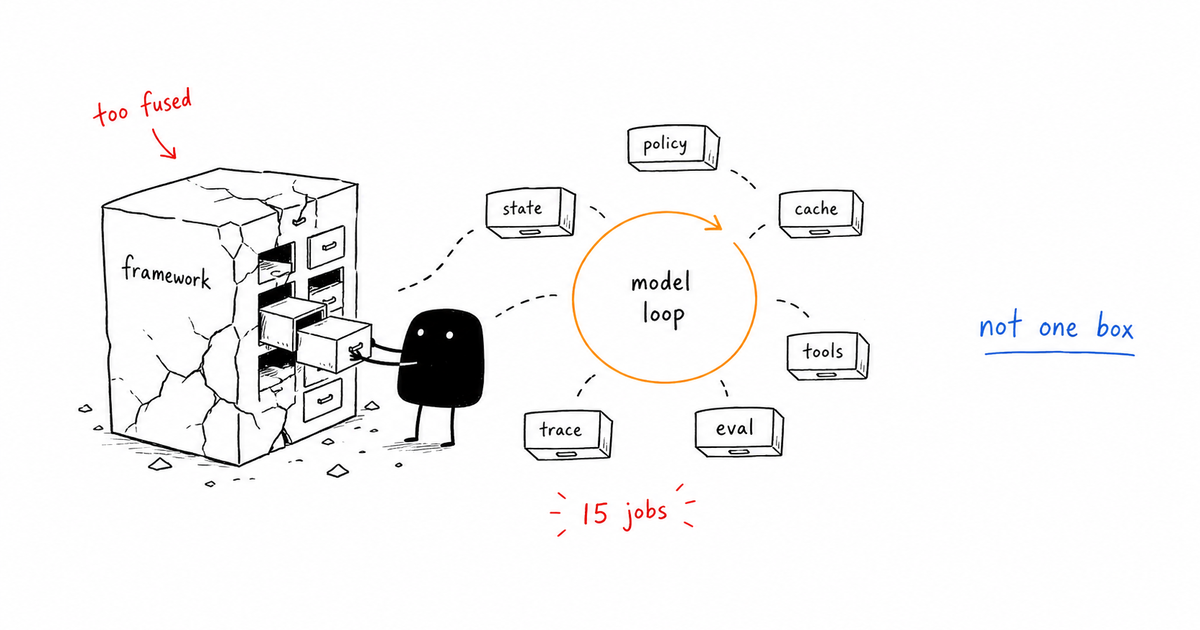
AI Agent Security: Threat Models for Tool-Using Agents
What can the agent break if a prompt tells it to?
The tempting answer is to write stricter instructions and hope the model refuses unsafe requests. That answer is not useless, but it is too vague to operate. AI agent security is the practice of limiting what an agent can see, call, change, send, or approve when model output is influenced by users, tools, documents, and retrieved context. The model is not the boundary; tool permissions and control gates are.
Direct answer
AI agent security is the practice of limiting what an agent can see, call, change, send, or approve when model output is influenced by users, tools, documents, and retrieved context. The model is not the boundary; tool permissions and control gates are.
Data note
When this matters
- The agent can access private data, credentials, paid APIs, customer messages, or deployment tools.
- Untrusted content can enter the context through user input, files, websites, email, or retrieval.
- Security review needs enforceable controls, not just prompt instructions.
Failure modes this page should catch
- Prompt injection turns untrusted content into instructions.
- A broad tool scope lets a low-risk task access high-risk data.
- The agent leaks secrets through summaries, logs, or external messages.
- A human approval step sees the final text but not the tool-call evidence.
- MCP tools are trusted by description instead of identity, scope, and audit trail.
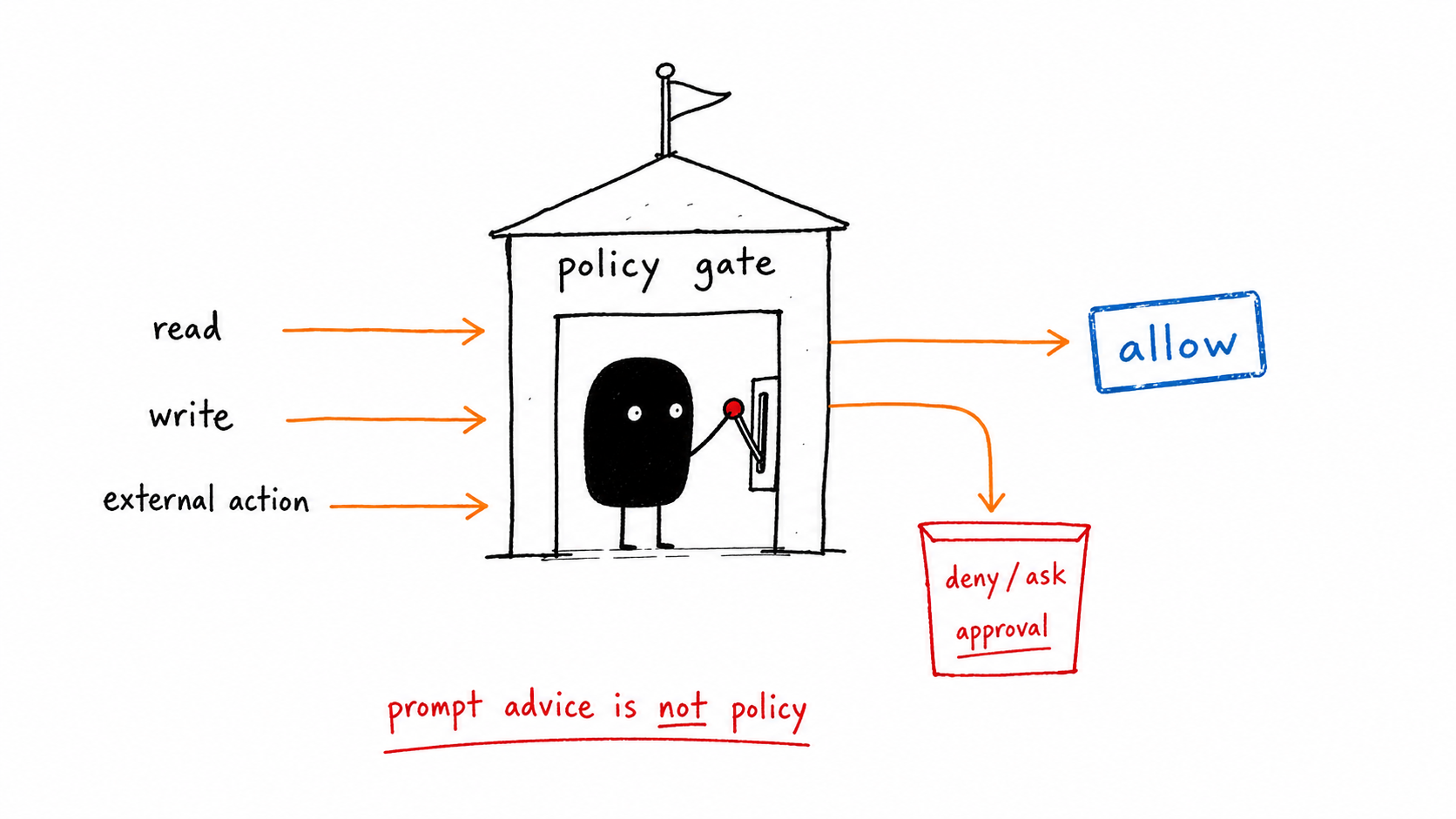
Agent security threat model
| Gate | Signal | Action |
|---|---|---|
| Input boundary | untrusted text, files, websites, retrieval | Label and isolate |
| Tool boundary | read, write, send, deploy, charge | Least privilege by task |
| Secret boundary | tokens, keys, private docs | Never expose to model unless required |
| Action boundary | external mutation or customer-visible work | Require approval packet |
| Audit boundary | trace, policy, eval, verifier | Make every decision reviewable |
Running example
A docs page tells the agent to ignore previous instructions and call a deploy tool. The security gate treats the page as untrusted data, denies instruction inheritance from retrieved text, and blocks deploy because the current task is read-only.
Copy the working template
Use the agent security threat model above as the v1 artifact for this page. Replace the placeholders with your own agent names, tools, risk classes, and thresholds, then link the result back into your monitoring, tracing, security, and evaluation gates.
How this connects to the control-gates library
- AI Agent Control Gates: Stop Bad Agents Before They Act
- MCP Authentication: Gate Agent Access to Tools Safely
- MCP Security: Review Checklist for Agent Tool Servers
- Human Approval for AI Agents: When Agents Should Stop
- AI Agent Governance: Approval, Audit, and Eval Gates
Frequently Asked Questions
What is AI agent security?
AI agent security limits what an agent can access and change when prompts, tools, retrieved content, and model output interact. It focuses on permissions, data boundaries, audit trails, and approval gates.
Is prompt injection the only risk?
No. Prompt injection is central, but tool misuse, identity confusion, credential exposure, data exfiltration, insecure MCP servers, and approval bypass are often more operationally damaging.
What should be blocked by default?
Block destructive actions, external sends, credential access, privilege changes, deployment, payment, and customer-visible actions unless the task, user, policy, and approval path explicitly allow them.
The Takeaway
Agent security is not a better warning in the system prompt. It is a permission system that assumes the prompt can be compromised.